Articles in the SQL category
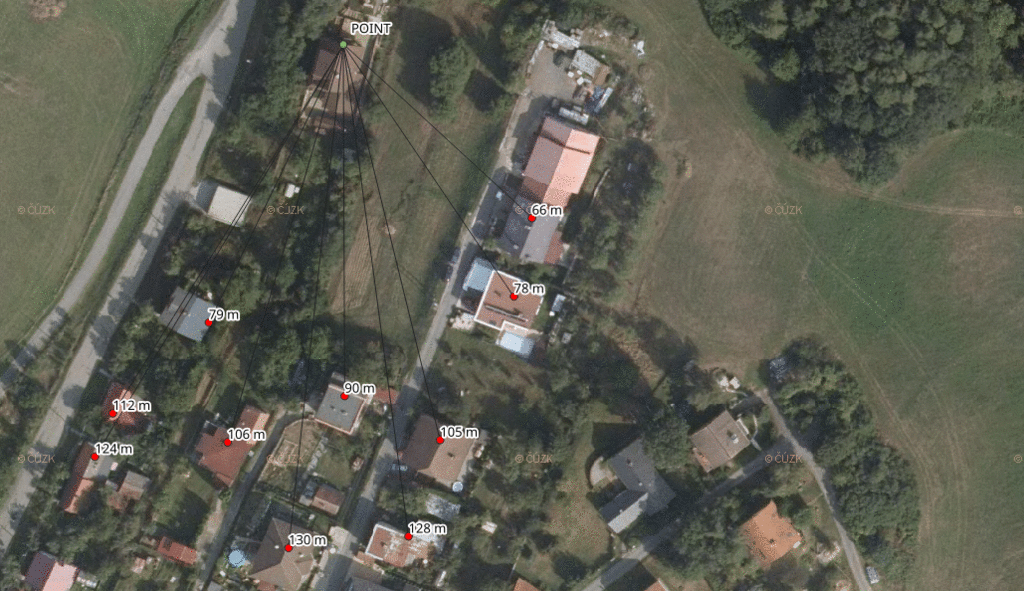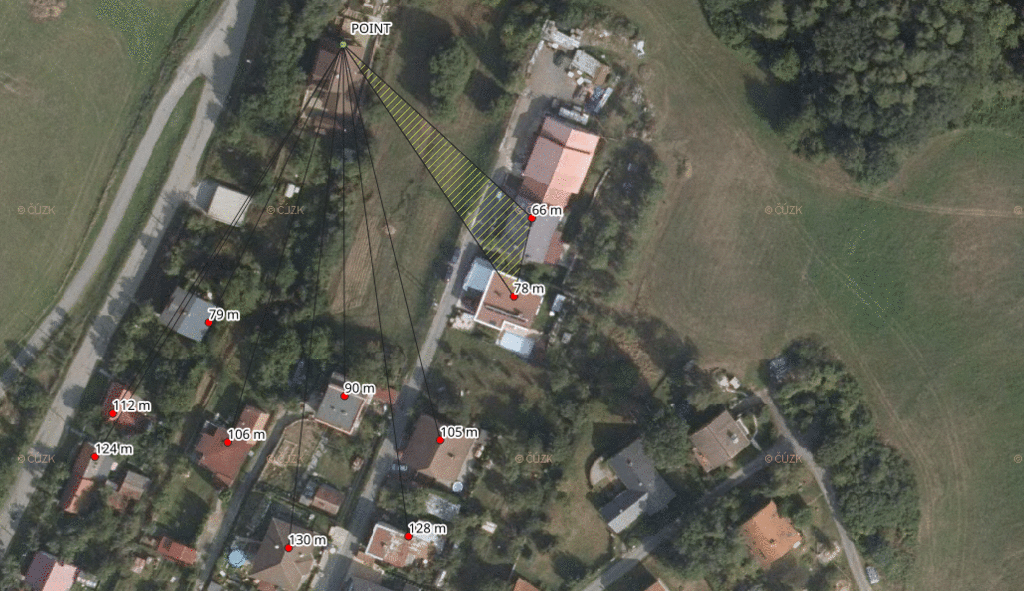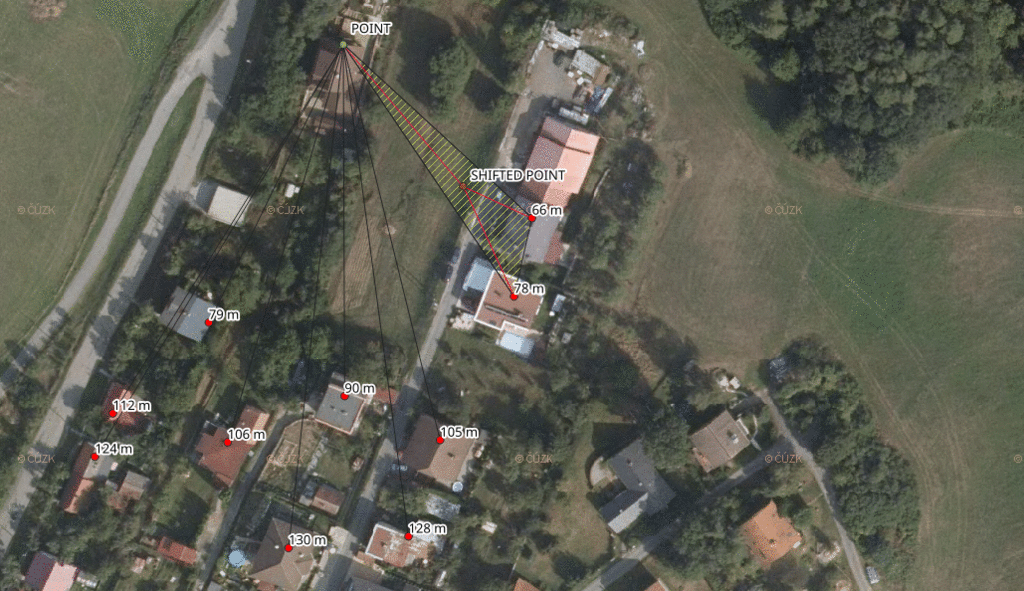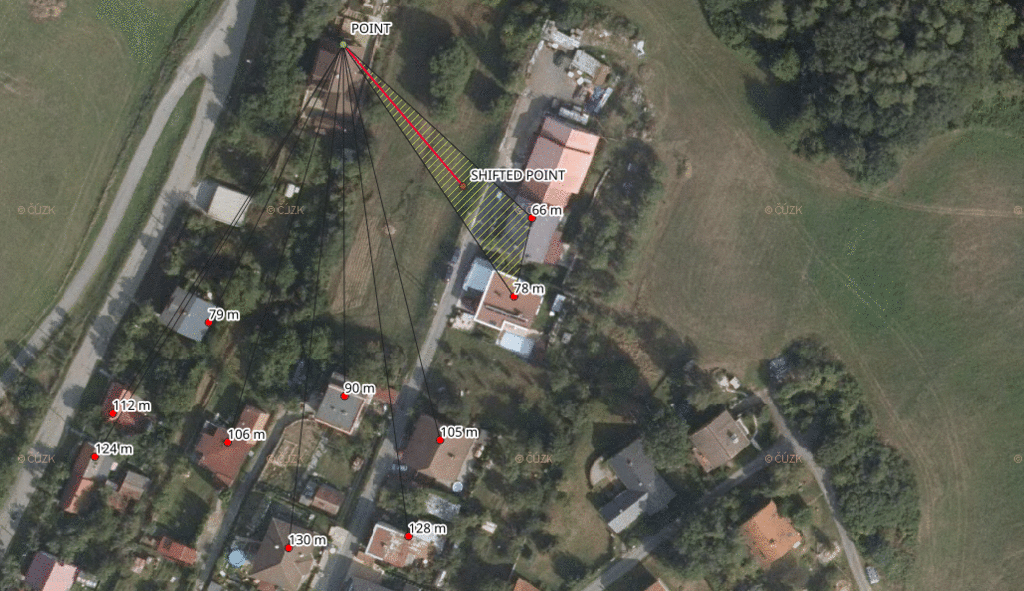
Among all the sensitive spatial data being collected through cellphones and credit cards, our address of residency is probably the most delicate one. Can it be anonymized/pseudonymized/obscured before you share it with your business partners?
Imagine given a set of address points for each of your clients and the set of all address points in the country, you should adjust it in the following way:
- find the two nearest address points for each address point of your client
- find the center of these two and the client address point
- measure the distance of the computed center to each of three points and keep the maximum value
- make the biggest distance even bigger by adding 10 % of its value
- ceil the value
- output the new position and the ceiled distance
This shifts each address point by a dynamic distance, giving us at least three points within the given distance (one of them being the original address point).
SELECT
tmp.code,
ST_X(tmp.new_position) x,
ST_Y(tmp.new_position) y,
ceil(MAX(biggest_distance) + MAX(biggest_distance) * 0.1) round_distance
FROM (
SELECT
tmp.code,
tmp.geom,
ST_Centroid((ST_Union(two_closest_points, tmp.geom))) new_position,
-- get distance to two closest points and the client address point
ST_Centroid((ST_Union(two_closest_points, tmp.geom))) <-> (ST_DumpPoints(ST_Union(two_closest_points, tmp.geom))).geom biggest_distance
FROM (
SELECT
r1.code,
r1.geom,
ST_Union(neighbours.geom) two_closest_points
FROM address_points r1,
LATERAL (
-- keep two closest points to each client address point
SELECT
r2.code,
r2.geom,
r1.geom <-> r2.geom distance
FROM address_points r2
WHERE r1.code <> r2.code
ORDER BY r1.geom <-> r2.geom ASC
LIMIT 2
) neighbours
GROUP BY
r1.code,
r1.geom
) tmp
) tmp
GROUP BY
tmp.code,
tmp.geom,
tmp.new_position;
You might want to use LATERAL for tasks like this.
PostGIS upgrades used to be a nightmare. Broken dependencies, version mismatches, you name it. Upgrading PostgreSQL 10 with PostGIS 2.4 to PostgreSQL 11 on CentOS has been my mission impossible for two days. And it doesn’t seem to come to an end.
What? Why?
We’re running fairly large spatially enabled PostgreSQL 10 database cluster. To keep up with pretty fast development, I was hoping to pg_upgrade it to PostgreSQL 11.
Tried and failed
I’ve been trying different upgrade strategies with PostgreSQL 11 already running to no avail. Here comes the list.
Install PostGIS 2.4 to PostgreSQL 11 and pg_upgrade
yum install postgis24_11
systemctl stop postgresql-11
su postgres
/usr/pgsql-11/bin/pg_upgrade \
--check \
-b /usr/pgsql-10/bin/ -B /usr/pgsql-11/bin/ \
-d /var/lib/pgsql/10/data -D /var/lib/pgsql/11/data \
--link \
-U root \
-o ' -c config_file=/var/lib/pgsql/10/data/postgresql.conf' -O ' -c config_file=/var/lib/pgsql/11/data/postgresql.conf'
This results in:
Your installation references loadable libraries that are missing from the
new installation. You can add these libraries to the new installation,
or remove the functions using them from the old installation. A list of
problem libraries is in the file: loadable_libraries.txt
loadable_libraries.txt says the following:
could not load library "$libdir/postgis-2.4": ERROR: could not load library "/usr/pgsql-11/lib/postgis-2.4.so": /usr/pgsql-11/lib/postgis-2.4.so: undefined symbol: geod_polygon_init
Duckduckgoing I found the related PostgreSQL mailing list thread.
Build and install PostGIS 2.4 from source to PostgreSQL 11 and pg_upgrade
The bug report says there’s something wrong with proj4 version, so I chose proj49 and geos37.
yum install proj49 proj49-devel
wget https://download.osgeo.org/postgis/source/postgis-2.4.6.tar.gz
tar -xzvf postgis-2.4.6.tar.gz
cd postgis-2.4.6
./configure \
--with-pgconfig=/usr/pgsql-11/bin/pg_config \
--with-geosconfig=/usr/geos37/bin/geos-config \
--with-projdir=/usr/proj49/
make && make install
CREATE EXTENSION postgis fails with could not load library "/usr/pgsql-11/lib/postgis-2.4.so": /usr/pgsql-11/lib/postgis-2.4.so: undefined symbol: geod_polygon_init. Oh my.
Install PostGIS 2.5 to PostgreSQL 10 and pg_upgrade
Running out of ideas, I tried to install PostGIS 2.5 to our PostgreSQL 10 cluster and pg_upgrade.
The resulting error appeared almost instantly:
Transaction check error:
file /usr/pgsql-10/bin/shp2pgsql-gui from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/lib/liblwgeom.so from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/lib/postgis-2.4.so from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/address_standardizer.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/address_standardizer.sql from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/address_standardizer_data_us.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/address_standardizer_data_us.sql from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/postgis.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/postgis_sfcgal.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/postgis_tiger_geocoder.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
file /usr/pgsql-10/share/extension/postgis_topology.control from install of postgis25_10-2.5.1-1.rhel7.x86_64 conflicts with file from package postgis24_10-2.4.5-1.rhel7.x86_64
What the…
Build and install PostGIS 2.5 from source to PostgreSQL 10 and pg_upgrade
wget https://download.osgeo.org/postgis/source/postgis-2.5.1.tar.gz
tar -xzvf postgis-2.5.1.tar.gz
cd postgis-2.5.1
./configure \
--with-pgconfig=/usr/pgsql-10/bin/pg_config \
--with-geosconfig=/usr/geos37/bin/geos-config
make && make install
CREATE EXTENSION postgis fails with ERROR: could not load library "/usr/pgsql-10/lib/postgis-2.5.so": /usr/pgsql-10/lib/postgis-2.5.so: undefined symbol: GEOSFrechetDistanceDensify. Again? Really?
GEOSFrechetDistanceDensify was added in GEOS 3.7 (linked in ./configure), yet ldd /usr/pgsql-10/lib/postgis-2.5.so says:
linux-vdso.so.1 => (0x00007ffd4c5fa000)
libgeos_c.so.1 => /usr/geos36/lib64/libgeos_c.so.1 (0x00007f68ddf5a000)
libproj.so.0 => /lib64/libproj.so.0 (0x00007f68ddd07000)
libjson-c.so.2 => /lib64/libjson-c.so.2 (0x00007f68ddafc000)
libxml2.so.2 => /lib64/libxml2.so.2 (0x00007f68dd792000)
libm.so.6 => /lib64/libm.so.6 (0x00007f68dd48f000)
libSFCGAL.so.1 => /lib64/libSFCGAL.so.1 (0x00007f68dc9c0000)
libc.so.6 => /lib64/libc.so.6 (0x00007f68dc5f3000)
libgeos-3.6.3.so => /usr/geos36/lib64/libgeos-3.6.3.so (0x00007f68dc244000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007f68dbf3d000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f68dbd27000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f68dbb22000)
libz.so.1 => /lib64/libz.so.1 (0x00007f68db90c000)
liblzma.so.5 => /lib64/liblzma.so.5 (0x00007f68db6e6000)
/lib64/ld-linux-x86-64.so.2 (0x000055960f119000)
libCGAL.so.11 => /usr/lib64/libCGAL.so.11 (0x00007f68db4bd000)
libCGAL_Core.so.11 => /usr/lib64/libCGAL_Core.so.11 (0x00007f68db284000)
libmpfr.so.4 => /usr/lib64/libmpfr.so.4 (0x00007f68db029000)
libgmp.so.10 => /usr/lib64/libgmp.so.10 (0x00007f68dadb0000)
libboost_date_time-mt.so.1.53.0 => /usr/lib64/libboost_date_time-mt.so.1.53.0 (0x00007f68dab9f000)
libboost_thread-mt.so.1.53.0 => /usr/lib64/libboost_thread-mt.so.1.53.0 (0x00007f68da988000)
libboost_system-mt.so.1.53.0 => /usr/lib64/libboost_system-mt.so.1.53.0 (0x00007f68da783000)
libboost_serialization-mt.so.1.53.0 => /usr/lib64/libboost_serialization-mt.so.1.53.0 (0x00007f68da517000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f68da2fa000)
librt.so.1 => /usr/lib64/librt.so.1 (0x00007f68da0f2000)
I’m nearly desperate after spending two days trying to break through. I have ~ 300 GB of PostgreSQL data to migrate to the current version and there seems to be no possible way to do it in CentOS.
One more thing to note: using yum install postgis25_11 and CREATE EXTENSION postgis in v11 database fails with the exact same error like the one above. I really enjoy working with PostgreSQL and PostGIS, yet there’s hardly something I fear more than trying to upgrade those two things together.
I’ve been working on a book/storytelling pet project recently. Dealing with book events and keeping them in order was a task that was to be tackled sooner or later. While both frontend and backend of the app could deal with linked and ordered data, database might be just about the best place to do so.
What you might need a linked list for
You have a set of chronological events. The set is not complete at the beginning and position of events might be changed (e.g. their neighbouring events might change in time).
Implementation
Linked list is a perfect structure for such a case (see Wikipedia). You can keep your data in tact using just id and previous/next id.
CREATE TABLE public.events (
id integer generated always as identity primary key,
previous_id integer
);
COPY public.events (id, previous_id) FROM stdin;
7 \N
10 5
5 1
1 3
3 8
8 9
9 2
2 6
6 4
4 7
\.
Generating the list of events in the right order is the matter of running one recursive CTE query.
WITH RECURSIVE evt(id) AS (
SELECT
id,
previous_id
FROM events
WHERE previous_id IS NULL
UNION
SELECT
e.id,
e.previous_id
FROM events e
JOIN evt ON (e.previous_id = evt.id)
)
SELECT * FROM evt;
It gathers the first event (the one having the previous pointer set to NULL) and iteratively adds the following ones. Note that this version is actually the reverse implementation of the linked list, pointing to the previous instead of the next event. All it would take to change that, would be finding the event id not present in previous_id column as the first one instead of WHERE previous_id IS NULL.
With the data coming properly sorted to the client, all it has to do is rendering the list.
Posts in this series have described the basic automation of PostgreSQL backup/recovery strategy. The process itself consists of different periodic tasks that shouldn’t be executed manually. There are essentially two tools dedicated to periodic task running in Linux: cron and systemd.
Cron used to be my first choice of automation in Linux, as it’s very easy to use. On the other hand, it’s quite messy (running crontab -e under different users to find out which one has the job defined) and a bit difficult to test - many times I ran into a situation when underlying bash script executed just fine, while cron job kept failing for reason unknown.
My own cron experience together with a few words from a workmate brought me into the arms of systemd, which is a Linux system and service manager. It’s capable of running periodic tasks just like cron, yet making it more transparent.
Important bits
Understanding the whole systemd is way out of scope of a poor GIS guy, yet I managed to tame three important parts of the ecosystem:
Services
Service is a configuration saved inside “.service” file specifying what you want systemd to do. Following code shows how you can tell systemd to vacuum your database once in a while.
[Unit]
Description=CR vacuumdb
OnFailure=unit-status-mail@%n.service unit-status-slack@%n.service
Wants=cr-sunday.timer
[Service]
User=postgres
Group=postgres
Type=simple
ExecStart=/bin/bash /usr/local/sbin/pgsql-vacuumdb.sh --port %i
[Install]
WantedBy=cr-sunday.target
Unit files come with several handy features. First of all, they are orchestrated with systemctl. Second, any service configuration file containing @ in its filename might be symlinked/copied and run for different instances. Third, notice OnFailure directive in the code above. If anything goes wrong, systemd might serve as a postman delivering the bad news. I set up both e-mail and Slack notifications and they’ve been working like a charm ever since.
On top of that, I find systemd orchestration much easier to test and maintain compared to cron.
With the above code saved in /lib/systemd/system/[email protected], you can copy the file to /lib/systemd/system/[email protected], /lib/systemd/system/[email protected] etc. If you look at ExecStart part of the service file, you’ll notice %i being used at the end - a placeholder replaced with the string between @ and .service in the filename.
This systemd service file is no more than a simple wrapper around the following bash code. We run three different database clusters on one machine and this approach makes their maintenance pretty comfortable.
#!/bin/bash
#
# @author: Michal Zimmermann <[email protected]>
# Vacuums the whole database cluster running on a given port.
while [[ $# > 0 ]]
do
key="$1"
case $key in
-p|--port)
PORT="$2"
shift
;;
*)
echo "Usage: `basename $0` --port|-p [port_number]"
exit 1
;;
esac
shift
done
if [[ -z "$PORT" ]]
then
echo "Port not provided!"
$0 *
exit 2
fi
/usr/bin/vacuumdb -U postgres -p $PORT --all --full --analyze
What you get so far is the possibility to run systemctl start pgsql-vacuumdb@5432 instead of calling the underlying bash code manually. Not much, really. That’s where timers come to the party.
Timers
Timer files ends with “.timer” and are responsible for running services on given time. The code below, coming from /lib/systemd/system/cr-sunday.timer file runs the pgsql-vacuumdb service every Sunday at 3:45 am.
[Unit]
Description=CR Sunday timer
[Timer]
OnCalendar=Sun *-*-* 03:45
Persistent=yes
Unit=cr-sunday.target
[Install]
WantedBy=multi-user.target
Targets
Target files end with “.target” and are used to group units in general. In our case, the target file for vacuumdb service is as simple as the following code.
[Unit]
Description=CR Sunday target
StopWhenUnneeded=yes
Targets might be called by other targets. Running systemctl start cr-sunday.target would eventually lead to running all the services wanted by that target.
As I already mentioned, I find systemd services easy to code and test. If any of them should fail, you’d find a message in syslog or via systemctl status pgsql-vacuumdb.
There is a bunch of periodic database-related tasks in a life of PostgreSQL administrator. Some should be done daily, others weekly, others can wait for a whole month. Many of them are essential for your database health. Forget to run such a task or screw up the run accidentally, and you’ll be snowed under with fixing your database.
Those tasks are easily done with bash, which is the first step to full automation. Following tasks are perfect candidates to be implemented as bash scripts:
- full backups (both creation and removal)
- WAL backups (both creation and removal)
- vacuum
- pgBadger log analysis (both creation and removal)
- log maintenance (if you don’t use log rotate)
Full backup creation is just one example of how powerful bash can be.
#!/bin/bash
#
# @author: Michal Zimmermann <[email protected]>
# Creates base backup.
CUR_DIR=$(dirname "$0")
if [[ ! -f ${CUR_DIR}/pgsql-common.sh ]]
then
echo "pgsql-common.sh not found!"
exit 1
fi
source "${CUR_DIR}/pgsql-common.sh"
source "$CONFIG"
if [[ -d ${CR_BASE_BACKUP_DIR}/${CR_LABEL} ]]
then
echo "${CR_BASE_BACKUP_DIR}/${CR_LABEL} already exists and is not empty!"
exit 2
fi
pg_basebackup \
--pgdata=${CR_BASE_BACKUP_DIR}/${CR_LABEL} \
--format=plain \
--write-recovery-conf \
--wal-method=stream \
--label=${CR_LABEL} \
--checkpoint=fast \
--progress \
--verbose
if [[ $? -gt 0 ]]
then
rm -rf ${CR_BASE_BACKUP_DIR}/${CR_LABEL}
echo "pg_basebackup on ${CR_LABEL} failed!"
exit 3
fi
tar -czf ${CR_BASE_BACKUP_DIR}/${CR_LABEL}.tar.gz ${CR_BASE_BACKUP_DIR}/${CR_LABEL} && rm -rf ${CR_BASE_BACKUP_DIR}/${CR_LABEL}
As you probably noticed, a pgsql-common.sh file is sourced at the beginning of the script. This script in turn just loads the proper config file that provides variables to other, devops, scripts. As you might need those variables in several of your scripts, it is a good idea to put their load to a separate file.
#!/bin/bash
#
# @author: Michal Zimmermann <[email protected]>
# Sourced in pgsql-*.sh scripts.
while [[ $# > 0 ]]
do
key="$1"
case $key in
-c|--config)
CONFIG="$2"
shift
;;
*)
echo "Usage: `basename $0` --config|-c [config_file]"
exit 1
;;
esac
shift
done
# /Input parameters
if [[ -z "$CONFIG" ]]
then
echo "Config file is not set! See the script usage below."
$0 *
exit 2
fi
if [[ ! -f "$CONFIG" ]]
then
echo "$CONFIG not found!"
exit 3
fi
A config file might remain as simple as this:
# Base backup location
export CR_BASE_BACKUP_DIR="/mnt/backup/symap/base/"
# WAL backup location
export CR_WAL_BACKUP_DIR="/mnt/backup/symap/wal"
# PostgreSQL WAL location
export CR_PG_XLOG_DIR="/var/lib/postgresql/10/symap/pg_wal"
export CR_PG_LOG_DIR="/var/lib/postgresql/10/symap/pg_log"
# Base backup pattern (set to YYYYMMDD)
export CR_LABEL=symap_$(date +%Y%m%d)
export PGPORT=5432
Another, likely the simplest, example is a vacuumdb task:
#!/bin/bash
#
# @author: Michal Zimmermann <[email protected]>
# Vacuums the whole database cluster running on a given port.
while [[ $# > 0 ]]
do
key="$1"
case $key in
-p|--port)
PORT="$2"
shift
;;
*)
echo "Usage: `basename $0` --port|-p [port_number]"
exit 1
;;
esac
shift
done
if [[ -z "$PORT" ]]
then
echo "Port not provided!"
$0 *
exit 2
fi
/usr/bin/vacuumdb -U postgres -p $PORT --all --full --analyze
Tips
- Always test your bash scripts before production deployment. Even a single line of code might lead to a very different, possibly unexpected, outcome.
- Try to stay as defensive as possible. Imagine a variable did not get sourced properly. Is it going to blow your database? Trust me, I know what I am talking about (see the tweet below).
Pitfalls
You do not want to run your bash scripts by hand. You probably do not want them to be run by cron. You want to run them with systemd. More on this next time.